
Por qué borrar datos cuando se tiene la posibilidad de redactar.

En el blog anterior de esta serie, expliqué cómo esperan los consumidores que una empresa gestione sus datos, especialmente en el contexto del acceso de ‘invitado’. ¿Cuándo se eliminarán definitivamente esos datos?
¿Quién tendrá acceso a ellos antes de su eliminación? ¿Cómo se almacenan los datos de forma segura?
Deuda de privacidad retroactiva
Los datos de pedidos de ‘invitados’ son tan solo un ejemplo de la ‘deuda de privacidad retroactiva’ que reside en la mayoría de los sistemas ERP. Se trata de datos que claramente no tienen motivos legales que justifiquen su conservación y que, por lo general, no se han eliminado debido a la complejidad de purgar estos datos en el sistema ERP. Esto también podría aplicarse a los sistemas CRM, aunque en la mayoría de los casos estos se han diseñado teniendo en cuenta que algunos serán temporales e incluyen mecanismos para su eliminación cuando ya no sean necesarios.
Los principios básicos de los sistemas ERP, y desde luego de SAP ERP, eran en realidad opuestos: plena integración y trazabilidad de todos los datos en todo momento. Me refería a esto cuando se implantó por primera vez el RGPD y el reto que suponía para el ‘Derecho al olvido’. Esto significa que la mayoría de las empresas que utilizan SAP acumulan algunos datos cuya permanencia en sus sistemas es sencillamente injustificable.
Naturalmente, también hay otros ejemplos de ‘deuda de privacidad retroactiva’, como los empleados que dejaron la organización hace tiempo. Cuanto más laxa sea la relación con el empleado, menor será el periodo durante el cual debemos conservar sus datos. Podrían citarse como ejemplo los trabajadores temporales de los sectores minoristas que pueden volver o no al año siguiente, o los contratistas que se han contratado para un proyecto específico a corto plazo.
Otro ejemplo típico de sectores en los que las adquisiciones y desinversiones son frecuentes es el de los empleados/clientes/proveedores que forman parte de una empresa que se vendió hace mucho tiempo. O incluso los datos de un sistema que se adoptó como parte de una adquisición, pero que nunca formó parte de la empresa adquirida. Hace diez años, cuando se realizaban adquisiciones apenas existía concienciación sobre la privacidad de los datos. La transferencia de sistemas y datos necesarios para el rendimiento de la empresa era el único objetivo del proyecto técnico y si se incluían algunos datos adicionales, ¿a quién le importaba? Ahora los proyectos de fusiones y adquisiciones deben tomarse muy en serio la privacidad de los datos, al igual que en cualquier otro proyecto: ‘Por defecto y desde su diseño’.
Eliminación de datos en SAP, archivado (SAP ILM) o simplemente nada
La eliminación de datos de sistemas ERP, y en particular de SAP, plantea dos grandes retos:
- Trazabilidad de los cambios en el sistema
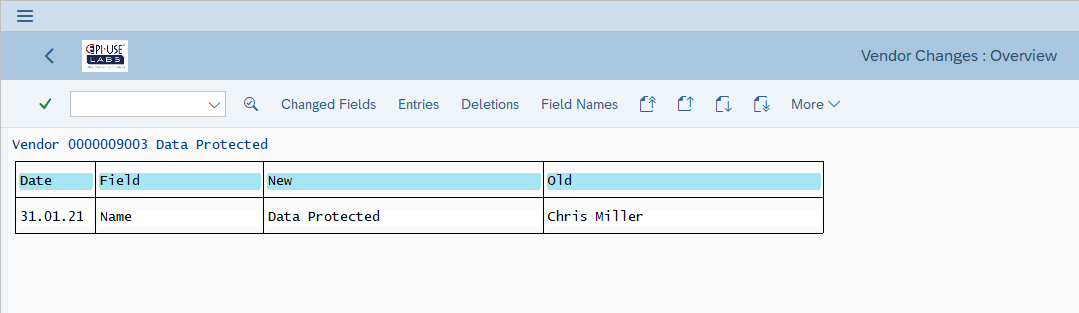
Si los usuarios de la empresa simplemente cambian los datos a través de transacciones estándar, el sistema guarda registros de los cambios y, por tanto, también de los datos anteriores como, por ejemplo, los documentos de cambio de proveedor/cliente/BP.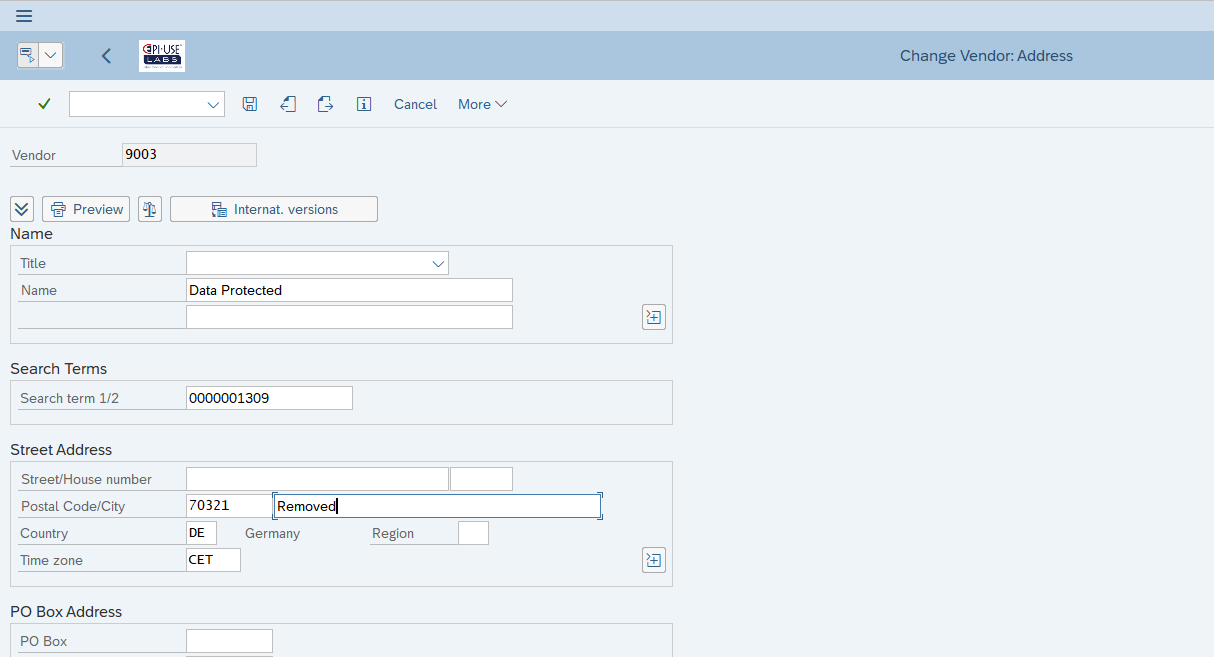
- Interconectividad de los sistemas ERP
Si, en cambio, vamos directamente al nivel de tabla y eliminamos los registros que contienen estos datos personales, se producirían incoherencias en el sistema. Por ejemplo, los pedidos de venta que hacen referencia a una clave de cliente principal que ya no existe.
La única manera estándar de eliminar los datos para que ninguno de ellos suponga un problema es marcar los datos para su eliminación y luego archivarlos. Esto traslada los datos a un archivo independiente en el sistema operativo, en el que los datos aún pueden leerse desde el sistema SAP, pero nunca modificarse. La finalidad del archivado nunca ha sido el deshacerse de los datos personales históricos del sistema, aunque se puede lograr eliminando los ficheros de archivado. El gran inconveniente de esto, sin embargo, es que el proceso de archivado requiere archivar primero cualquier transacción que haga referencia a los datos maestros. Así, para archivar cada transacción, primero hay que archivar las subsiguientes transacciones. Esto significa, por ejemplo, que para archivar los datos maestros de los clientes primero hay que archivar los pedidos de venta, pero para archivar el pedido de venta primero hay que archivar la entrega... Y así sucesivamente hasta los documentos de contabilidad. La finalidad de este proceso no es únicamente la eliminación de datos confidenciales o personales, y eso se nota al aplicarse a ese reto.
S/4HANA
¿Qué sería de un blog de SAP si no mencionara S/4HANA? Pues bien, al emprender o preparar una migración a S/4HANA, se suele plantear tanto la limpieza como el archivado de datos. Esto no debe confundirse con la gestión de la deuda de privacidad retroactiva. La limpieza de datos rara vez se ocupa de la purga de datos innecesarios, a menos que el proyecto sea un escenario nuevo en el que esta deuda retroactiva pueda simplemente dejarse atrás. Por lo general, se trata del proceso de integración de clientes y proveedores y de la eliminación de la duplicación de registros maestros, o de la corrección de errores de formato. En proyectos con infraestructura previa, el archivado se contempla para reducir el tamaño potencial de la base de datos del futuro sistema, y la mayor parte del ahorro de espacio se consigue eliminando grandes cantidades de datos transaccionales en lugar de datos maestros históricos.
Alternativa: la redacción
Si la depuración total de nuestra deuda de privacidad retroactiva no supone un gran ahorro de espacio y el proceso plantea muchos y difíciles retos, además de la posible eliminación de datos valiosos no confidenciales, como la distribución geográfica de los clientes o la capacidad de elaboración de informes por género de los empleados históricos, sin duda hay una manera mejor. El problema de dejar que la empresa se limite a cambiar los datos para eliminar los valores identificables es que el mismo cambio es objeto de seguimiento. Si en cambio nos dirigimos al nivel de tabla y reemplazamos cualquier dato confidencial o identificable, podremos hacerlo desde que los datos existen, no será un cambio a partir de hoy.
Ahora bien, toda la información adyacente que puede seguir siendo útil para la elaboración de informes podrá conservarse. Y cualquier dependencia de las relaciones externas clave en los datos transaccionales, o incluso las referencias de los datos maestros relacionados (por ejemplo, direcciones, datos de estructura de descomposición del trabajo (EDT), personas de contacto) seguirán intactas.
Ejemplo práctico 1: datos maestros de proveedor
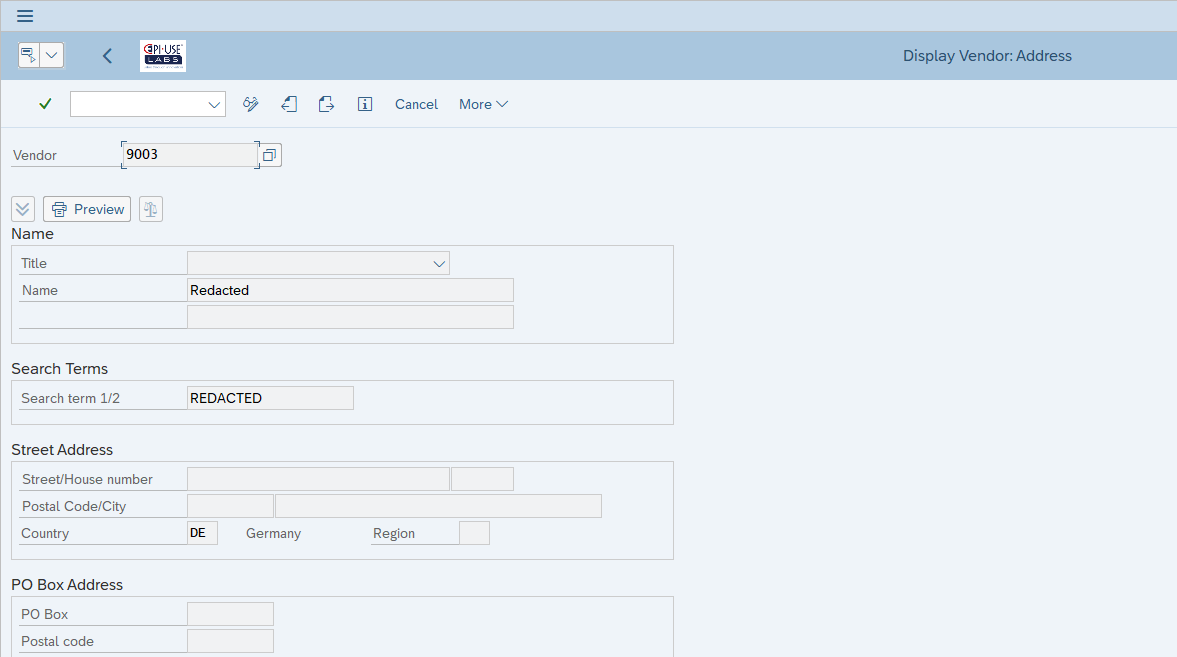
En este caso vemos el mismo proveedor que hemos analizado anteriormente, pero ahora se han redactado los campos confidenciales de LFA1, LFB1 y ADRC mediante programación.
Todos los documentos de cambios se han eliminado (ya que los valores originales pueden seguir estando ahí).

Ejemplo práctico 2: datos maestros de cliente en pedidos
En este ejemplo, los datos maestros de KNA1, ADRC, etc. que se actualizan a través de XD02 pueden verse en la transacción de pedidos de venta (VA03) debido al enlace en la tabla VPBA. En este ejemplo, no es necesario realizar ningún cambio en el pedido. Todos los datos personales son transferidos. Por tanto, los cambios, similares a los realizados en el primer ejemplo respecto al proveedor, ahora se realizan en los datos maestros del cliente y garantizan además que los pedidos de ese cliente ya no muestren valores de datos personales.
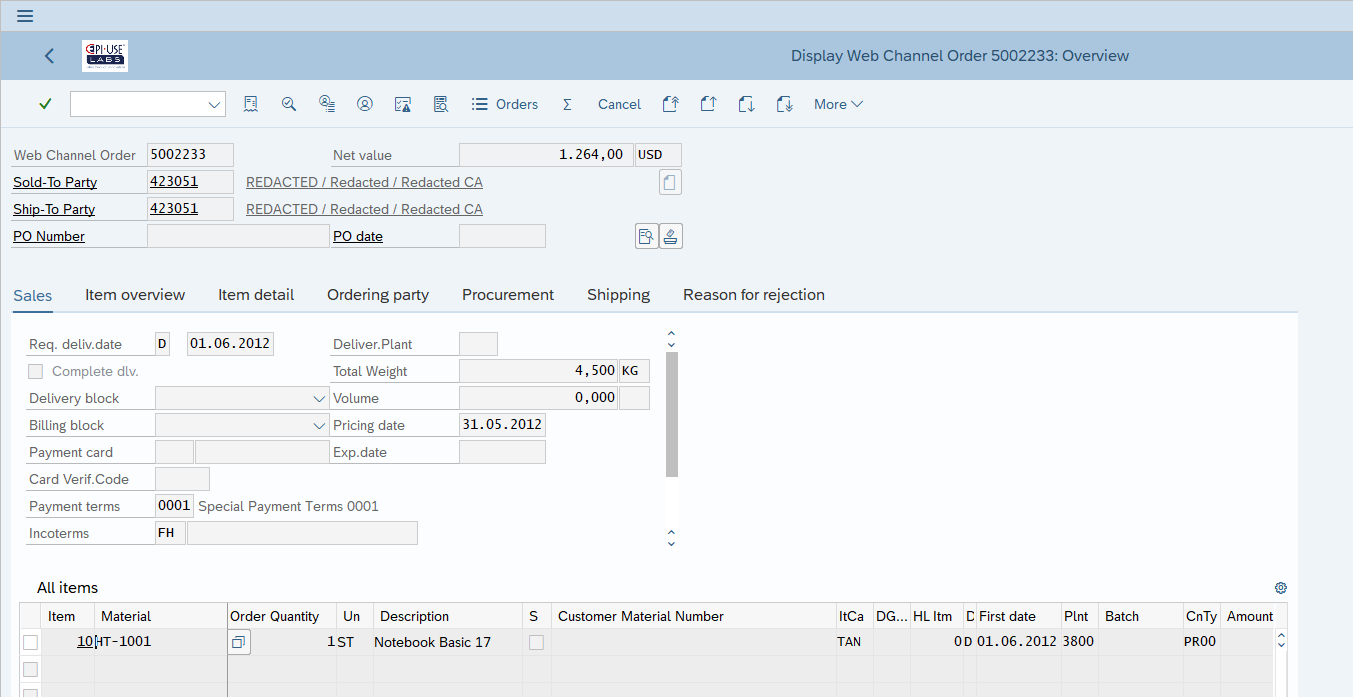
Ejemplo práctico 3: direcciones personalizadas en los pedidos
En el blog anterior, me centré en el tema de las direcciones personalizadas o a medida, ya sea como parte de un proceso de compra de ‘invitado’ o cuando la dirección heredada del registro de datos maestros se ha adaptado para este pedido específico. Ahora vemos un registro de direcciones distinto vinculado al pedido en VPBA y, en su lugar, esos datos se han redactado en ADRC mediante programación.
Todo esto parece bastante fácil, pero ¿dónde está la trampa?
El reto de configurar sus propios programas de redacción es la cantidad de lugares en los que pueden residir los datos. Encontrarlos todos es posible, pero es algo que debe revisarse también si los procesos empresariales cambian y se actualiza SAP en el futuro. Algunos ejemplos son:
- Documentos de cambios en la tabla CDHR y el clúster CDPOS
Aunque no generemos documentos de cambios en nuestro proceso de redacción, aún podrían existir algunos y podrían incluir cambios reales como, por ejemplo, el cambio de dirección de un cliente. Tanto los valores antiguos como los nuevos son datos personales de ese consumidor. - ADRC, ADR2, ADCP, ADRP, etc.
Dependiendo de la personalización del sistema y del tipo de datos de dirección, estos valores de datos personales pueden almacenarse en distintos campos de diferentes tablas. Es fundamental localizarlos todos, pero solo los que afecten a las direcciones previstas y no tomar sin querer una dirección personalizada, por ejemplo. - Datos del clúster
Las tablas transparentes suelen ser fáciles de manejar e incluso los clústeres como CDPOS en los que la clave no se encuentra en los datos sin procesar del clúster. No obstante, en algunos casos (como los datos de HCM que abordaré en el próximo blog) el identificador real es más difícil de localizar: por ejemplo, el número de empleado en el clúster PCL2. Sin embargo, la ubicación de los datos personales en el clúster puede variar de un sistema a otro e incluso de un registro a otro, en función del país del empleado, por ejemplo, o de otras propiedades del registro de datos en cuestión.
Tecnología de redacción de EPI-USE Labs
Hemos desarrollado un software que las organizaciones pueden utilizar directamente para realizar sus propias redacciones, ya sea de forma interactiva a peticiones individuales o como parte de una aplicación periódica automática de un período de retención. También ofrecemos servicios y asesoramiento de ayuda para la gestión de una importante depuración inicial de la deuda de privacidad retroactiva. Si desea recibir asistencia de expertos, póngase en contacto con nosotros.
Se trata de realizar unas actividades mínimas para cumplir con los requisitos de minimización de datos históricos a efectos de cumplimiento de la normativa.
Leave a Comment: