
Quello della privacy dei dati è un tema sul quale si concentrano da tempo le attenzioni delle organizzazioni, chiamate a riflettere su come aderire alle normative che tutelano i diritti alla privacy di ciascun individuo. Oltre all’Europa, in cui è stato introdotto il GDPR come nuovo quadro normativo con cui disciplinare la privacy dei dati, in altri paesi del mondo le legislazioni nazionali sono state aggiornate per integrare il tema, ad esempio il POPI Act in Sudafrica, l’LGPD in Brasile e il CCPA in California.

Quello della privacy dei dati è un tema sul quale si concentrano da tempo le attenzioni delle organizzazioni, chiamate a riflettere su come aderire alle normative che tutelano i diritti alla privacy di ciascun individuo. Oltre all’Europa, in cui è stato introdotto il GDPR come nuovo quadro normativo con cui disciplinare la privacy dei dati, in altri paesi del mondo le legislazioni nazionali sono state aggiornate per integrare il tema, ad esempio il POPI Act in Sudafrica, l’LGPD in Brasile e il CCPA in California.
Se state leggendo questo blog è probabile che siate già in una fase di valutazione delle esigenze di sicurezza dei dati della vostra organizzazione, e forse avete avviato l’implementazione di soluzioni per alleviare alcune delle vostre preoccupazioni. Oggi vorrei parlarvi di alcuni aspetti dell’esperienza che ho maturato lavorando per EPI-USE Labs su svariati progetti di privacy dei dati, in particolare nel contesto dei sistemi SAP®.
Sono generalmente tre le posizioni che si delineano con nitidezza quando si fa il punto attorno alle esigenze di privacy dei dati:
-
Per i responsabili dei test e i proprietari del prodotto la priorità è chiaramente quella di poter mettere alla prova i processi su dati “reali” (ossia che si portano dietro tutte le stranezze della produzione, inclusi gli aspetti non corretti al 100%).
-
Per i team di protezione dei dati il punto inderogabile è che nessuna informazione personale identificabile esca dalla produzione.
-
Per i team di IT e infrastrutture gli sforzi vanno diretti alla velocità ed efficienza con cui consegnare dati copiati e codificati all’ambiente non di produzione con interferenze ridotte al minimo.
Queste tre posizioni conflittuali vanno a complicare in particolare la possibilità di realizzare un ambiente operativo di sviluppo che si possa definire sicuro e fruibile. Con questo post voglio entrare nel merito di queste difficoltà nell’ottenere i dati allineati e simili a quelli della produzione che i Responsabili dei test vorrebbero vedere.
Vi propongo allora due scenari di dati:
Scenario 1
Un semplice esempio che vede un impiegato nell’ufficio acquisti alle prese con i codici fiscali in Spagna. Quando pensiamo alle informazioni personali identificabili il dipendente diventa un’area di interesse comune. Per analizzare la situazione e far emergere alcuni dei processi SAP standard con cui si archiviano i dati sensibili riporto qui un diagramma ad alto livello che mostra la relazione dei dati nell’oggetto dipendente.
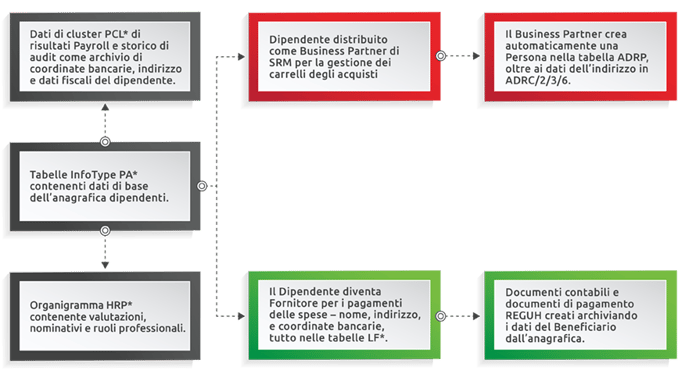
Nel modello dati SAP standard possono subentrare centinaia di campi dati sensibili. Non mancherebbero poi le personalizzazioni sopraggiunte nel corso del tempo, con la conseguente archiviazione di copie aggiuntive dei dati. Per tutti questi dati c’è una prima volta in cui devono essere popolati manualmente, il che comporta il rischio di errore umano di immissione. Nel corso degli anni è probabile che con il succedersi di correzioni, programmi di pulizia e riparazioni manuali da parte dell’azienda i dati perdano completamente la sincronizzazione.
Le stesse caratteristiche di integrazione e connessione che fanno la forza del sistema rischiano al contempo di renderlo più complesso quando la necessità è quella di mascherare o codificare i dati per rispettare la privacy dei dati.
Scenario 2
L’esempio si riferisce a una richiesta di un cliente di mascherare la partiva IVA in Spagna e Portogallo. In questo scenario la regola aziendale è particolarmente semplice: il campo STCEG in KNA1 deve essere il valore concatenato del paese e del campo STCD1 del cliente:
| KUNNR | LAND1 | STCD1 - KNA1 | STCD2 - KNA1 | STCEG - KNA1 |
| 0000000001 | ES | A12345678 | - | ESA12345678 |
Un’analisi dei dati può servirci a capire meglio la variazione nei dati. Gli elementi presi in considerazione sono la lunghezza e la coerenza di questa regola prima di qualsiasi attività di anonimizzazione. Dall’analisi ho riscontrato quanto segue:
-
sei diverse lunghezze di codici fiscali solo nel sistema nazionale spagnolo
-
10% di dati che non corrispondeva agli originali
-
un ulteriore 20% di esempi in cui un campo era vuoto
-
un 25% in cui erano riprodotte le regole di allineamento, ma non il previsto requisito del cliente
-
oltre 1.000 scenari diversi di coerenza quando sono stati sovrapposti nuovi paesi ed è stata considerata l’integrazione trasversale ai sistemi con il CRM.
Alla resa dei conti, appena il 35% dei dati rispondeva al requisito che il cliente aveva prefigurato come “mondo ideale” o mappatura più tradizionale.
Cosa ne consegue in termini di impatto?
Tornando ora alle mie tre priorità originarie, ossia come distribuire dati di produzione reali che si possano non solo mascherare per ovviare ai problemi della sicurezza ma anche creare in modo efficiente, occorre sapere come sono collegati i dati e capire quale ruolo riveste la qualità dei dati nel sistema.
-
Nel primo esempio , si vede come il semplice fatto di ospitare i dati InfoType elementari dei dipendenti è destinato a lasciare enormi quantità di dati sensibili senza anonimizzazione.
-
Nel secondo esempio, in cui dovevamo unicamente impostare i due campi di imposte, sarebbe necessaria la logica per ospitare 1163 scenari. I tempi di esecuzione per una simile operazione, quando si confrontano e prendono decisioni, supererebbero nettamente i tempi di inattività ammessi per l’aggiornamento e la codifica di un sistema.
In EPI-USE Labs lavoriamo al fianco dei clienti per analizzare i dati dei loro sistemi SAP e prevedere quando andranno incontro a problemi. Suggeriamo inoltre possibili soluzioni in modo da assicurare a ciascun proprietario di processo il miglior esito possibile.
Vi invito a seguire questo webinar in cui ho discusso dell’analisi dei dati in SAP in un’ottica di sicurezza degli ambienti non di produzione. Nel corso dell’intervento offro inoltre una dimostrazione del software che utilizziamo in una sessione di workshop e analisi della privacy dei dati.

Lascia un commento: