
Perché eliminare quando basta mascherare?

Nell’ultimo blog di questa serie vi ho parlato delle aspettative dei consumatori in merito al trattamento dei loro dati da parte delle aziende, in particolare in riferimento agli accessi “guest”. Quando verranno rimossi definitivamente i dati?
Chi avrà accesso prima che ciò avvenga? Con che livello di sicurezza vengono conservati i dati?
Il “debito di privacy” sui dati accumulati
I dati degli ordini di utenti “guest” sono solo un esempio di quello che potremo definire un “debito di privacy” che riguarda i dati accumulati, insito nella maggior parte dei sistemi ERP. Si tratta di dati conservati senza una palese motivazione legale, e che generalmente non sono stati eliminati solo perché ripulire il sistema ERP da questi dati risulta troppo complesso. Lo stesso potrebbe valere per i sistemi CRM; ma nella maggior parte dei casi questi sono progettati con la consapevolezza che alcuni dati sono per loro natura temporanei e pertanto i sistemi CRM includono meccanismi per rimuovere i dati non più necessari.
I sistemi ERP, e di certo SAP ERP, si fondano invece da sempre sui principi opposti, ossia piena integrazione e tracciabilità costante di tutti i dati. Ho espresso questo concetto nelle primissime fasi di introduzione del GDPR e della sfida che esso poneva relativamente al “diritto all’oblio”. Ciò significa che la maggior parte delle aziende che utilizzano SAP si ritrovano con una quantità di moduli e dati che non possono nemmeno giustificare di avere ancora nei loro sistemi.
Naturalmente esistono anche altri esempi di “debiti di privacy” sui dati accumulati, che riguardano, ad esempio, i dipendenti che hanno lasciato l’azienda già da molto tempo. Meno stretto è il rapporto con l’azienda, più breve è il periodo per il quale i loro dati andrebbero conservati. Ne sono un esempio i collaboratori stagionali del commercio al dettaglio che potrebbero o meno tornare l’anno successivo, o anche le ditte esterne di cui un’azienda si avvale per progetti a breve termine.
Un altro esempio molto diffuso per i settori in cui acquisizioni e cessioni sono all’ordine del giorno, è costituito dai dipendenti/clienti/fornitori di attività liquidate già da tempo. O anche i dati contenuti in un sistema adottato nel quadro di un’acquisizione, ma che non è stato mai parte dell’attività acquistata. Dieci anni fa, quando si realizzava un’acquisizione, non ci si preoccupava più di tanto della questione della privacy. Il solo scopo del progetto era trasferire i sistemi e i dati necessari per lo svolgimento dell’attività e, a chi interessava se il passaggio coinvolgeva anche una piccola quantità di dati in più? Ai giorni d’oggi, nei progetti di fusione e acquisizione, la protezione dei dati è un aspetto da tenere rigorosamente in considerazione, esattamente come dovrebbe avvenire in qualsiasi altro progetto -
“By default e by design”.
Rimuovere i dati in SAP, archiviarli (SAP ILM) o niente
Sono due le sfide principali associate alla rimozione dei dati dai sistemi ERP e in particolare da SAP:
- La tracciabilità delle modifiche nel sistema
Se gli utenti di un’azienda accedono ai dati e li modificano con una normale operazione, il sistema tiene traccia delle modifiche, e quindi anche dei dati precedenti; ne sono un esempio i documenti di modifica di fornitori/clienti/partner commerciali: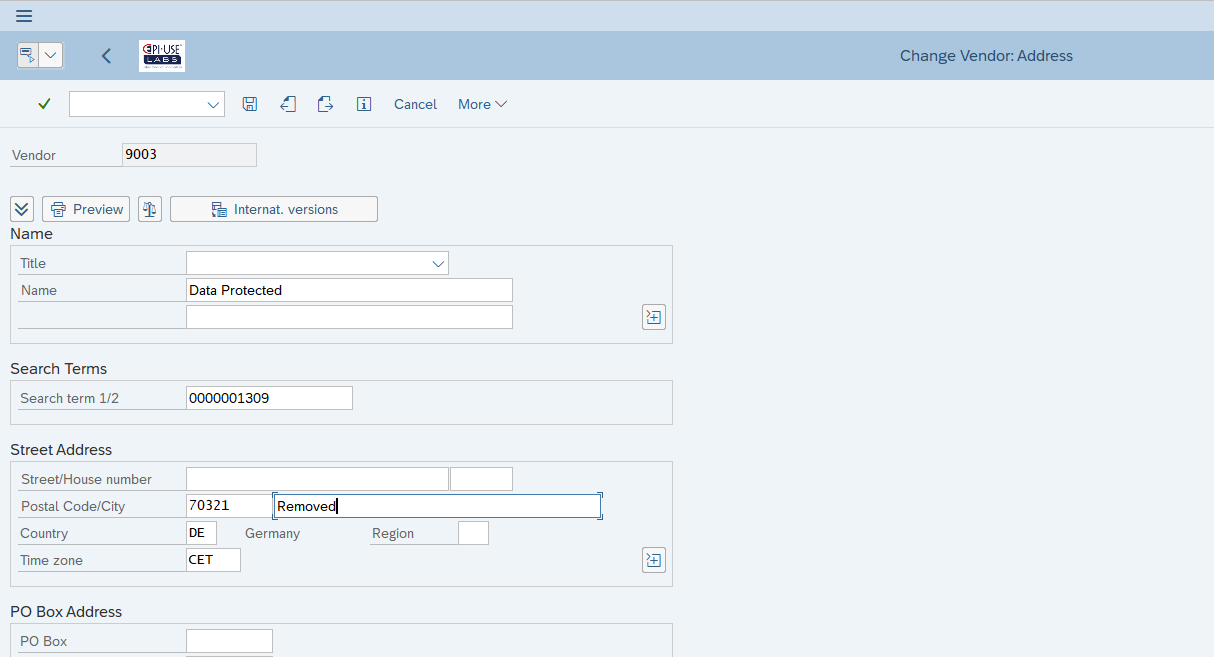
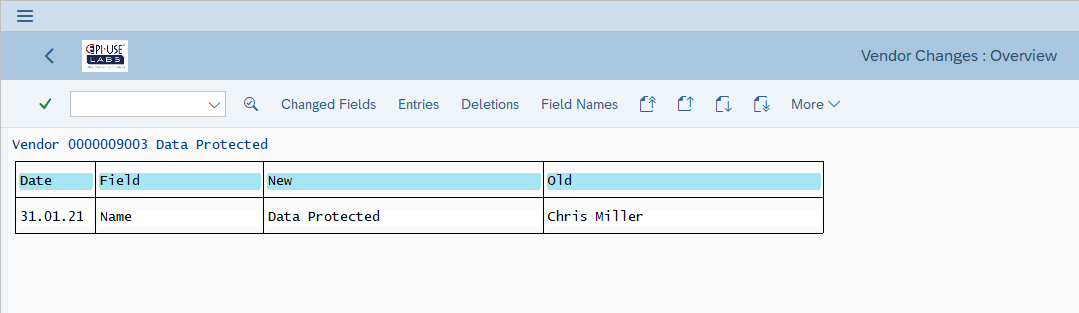
- L’interconnettività dei sistemi ERP
D’altro canto, se intervenissimo noi a livello di tabella cancellando i record contenenti questi dati personali, si creerebbero incongruenze nel sistema, come, ad esempio, nel caso di ordini di vendita riferiti al codice anagrafico di un cliente non più esistente.
Il solo modo standard per rimuovere dati specifici senza creare questo tipo di problema, è evidenziare i dati da eliminare e archiviarli. In questo modo i dati vengono trasferiti in un file separato nel sistema operativo, in genere in un percorso in cui continuano a poter essere letti dal sistema SAP, ma non possono più essere modificati. La finalità dell’archiviazione non è mai stata quella di liberare definitivamente il sistema da dati personali storici, ma questo obiettivo può invece essere raggiunto, eliminando i file di archivio. Il grande problema in questo senso, però, è che il processo corretto richiede che vengano archiviate prima tutte le transazioni contenenti un riferimento ai dati anagrafici. E per archiviare ogni singola transazione, prima è necessario archiviare le eventuali transazioni successive. Quindi, ad esempio, per archiviare l’anagrafica clienti occorre prima archiviare gli ordini clienti, ma per archiviare un ordine di vendita, prima deve essere archiviata la fornitura, ecc. e così per tutta la trafila fino ai documenti contabili. Questo processo non era stato pensato allo scopo di eliminare in modo mirato solo i dati sensibili o personali, e ciò appare evidente quando viene applicato proprio per risolvere questo specifico problema.
S/4HANA nella mischia
Cosa sarebbe un blog SAP senza nemmeno un accenno a S/4HANA? In effetti, quando si avvia o si prepara una migrazione a S/4HANA, in genere si parla di pulizia e archiviazione dei dati. Ma non confondiamo queste semplici considerazioni con l’affrontare veramente il problema del debito di privacy sui dati accumulati. La pulizia dei dati raramente ha a che fare con l’eliminazione mirata di dati indesiderati, a meno che non si tratti di un progetto greenfield in cui questo debito che riguarda i dati accumulati può essere semplicemente ignorato. Normalmente si tratta di processi CVI (Customer/Vendor Integration) per i quali si procede ad eliminare i duplicati presenti nei dati anagrafici o a correggere errori di formattazione. Per i progetti brownfield l’archiviazione viene presa in considerazione per ridurre le dimensioni potenziali del futuro database di sistema, e il maggior risparmio di spazio si ottiene togliendo grandi quantità di dati transazionali piuttosto che di dati anagrafici obsoleti.
L’alternativa è mascherare (redact)
Se eliminando i dati accumulati che ci espongono a questo “debito di privacy” non si ottengono grandi risparmi di spazio, e comunque questa procedura comporta sfide anche più complicate, come il rischio di eliminare preziosi dati non sensibili come la distribuzione geografica dei clienti o le capacità statistiche di genere nello storico dei dipendenti, possibile che non ci sia un’alternativa valida? Se l’azienda interviene cambiando i dati per rimuovere gli elementi identificabili, il problema resta perché la modifica stessa viene tracciata. Se invece accediamo noi direttamente a livello di tabella e sostituiamo tutti i dati sensibili o identificabili, possiamo intervenire all’origine dei dati, anziché come modifica a partire da oggi.
Ma tutte le informazioni correlate che potrebbero ancora essere utili per la reportistica verrebbero mantenute. Anche tutte le dipendenze da relazioni chiave esterne nei dati transazionali e i riferimenti legati a dati anagrafici correlati (ad esempio, indirizzi, dati WSB, persone di contatto, ecc.) resterebbero intatti.
Esempio pratico 1: Anagrafica fornitori
Qui vediamo lo stesso fornitore di prima, ma adesso i campi sensibili LFA1, LFB1, ADRC sono stati mascherati (redacted) in modo programmatico.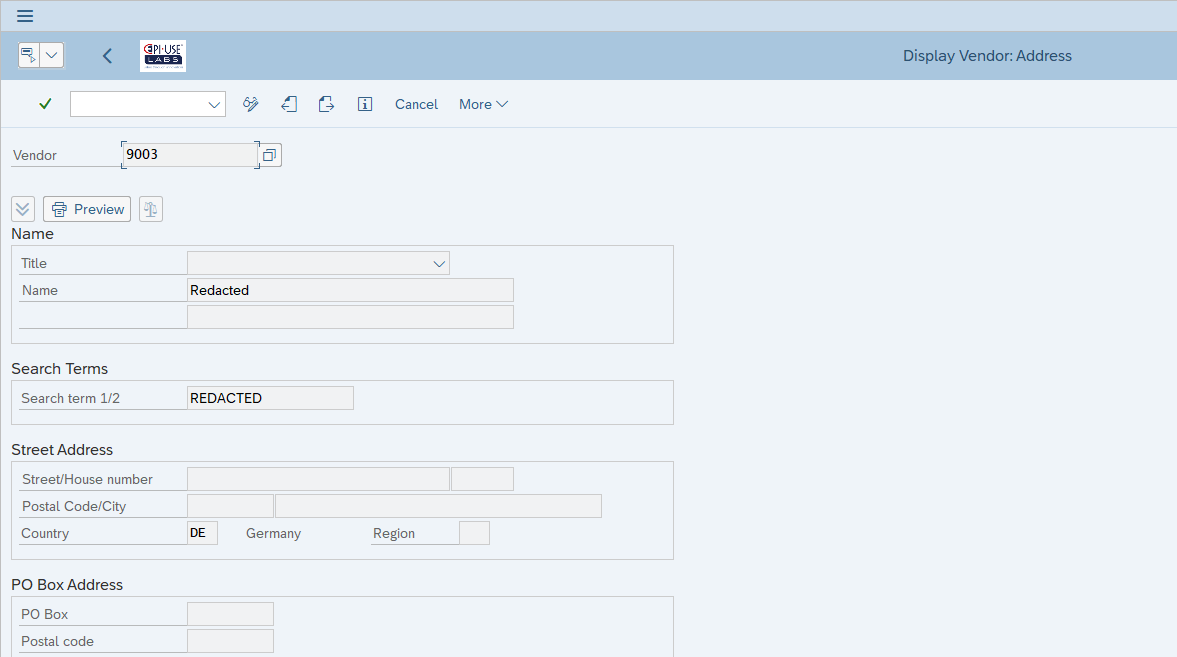

Con tutti i documenti di modifica eliminati (perché potrebbero contenere i valori originali)
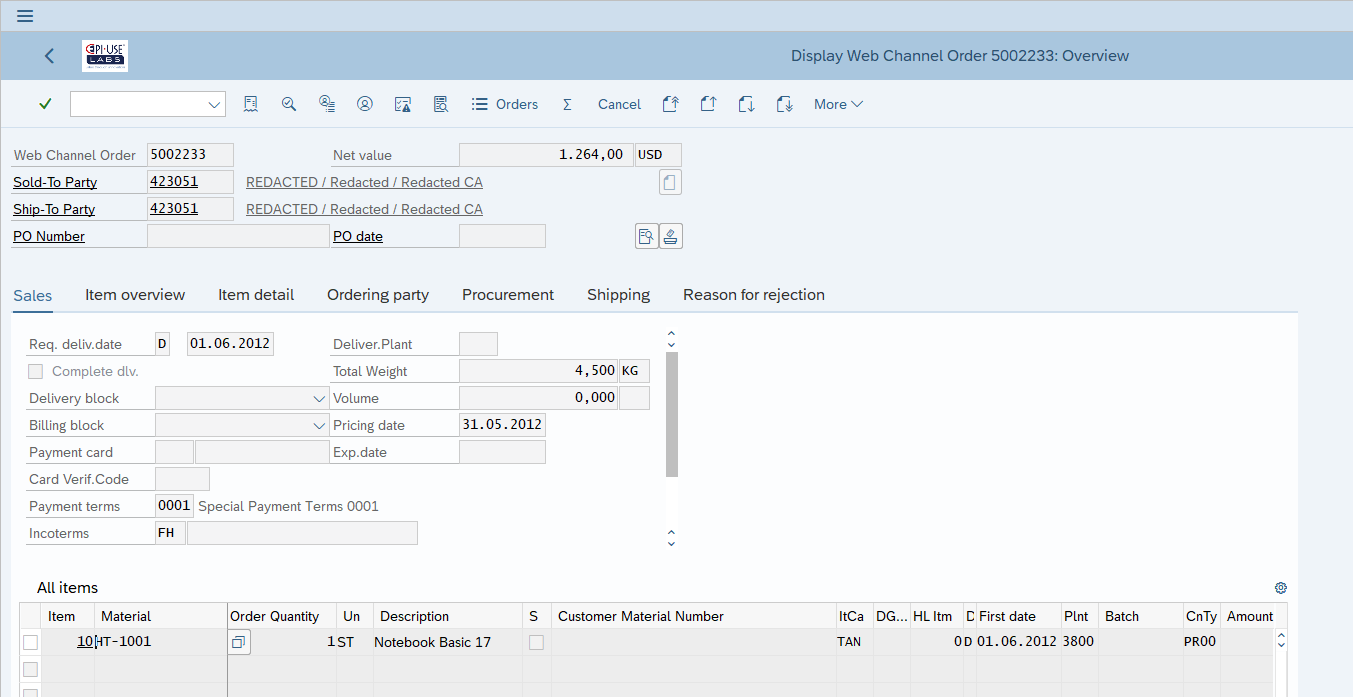
Esempio pratico n. 2: Dati anagrafici dei clienti negli ordini
In questo esempio, i dati anagrafici in KNA1, ADRC, ecc. che vengono aggiornati tramite XD02, sono visibili nella transazione Ordine di vendita (VA03) per la presenza del link nella tabella VPBA. In questo esempio non serve che apportiamo nessuna modifica all’ordine. Tutti i dati personali sono ripuliti. Le modifiche – simili a quelle che abbiamo fatto nel primo esempio per il fornitore, ma adesso riferite all’anagrafica clienti – garantiscono anche che gli ordini per quel cliente non mostrino più informazioni personali.
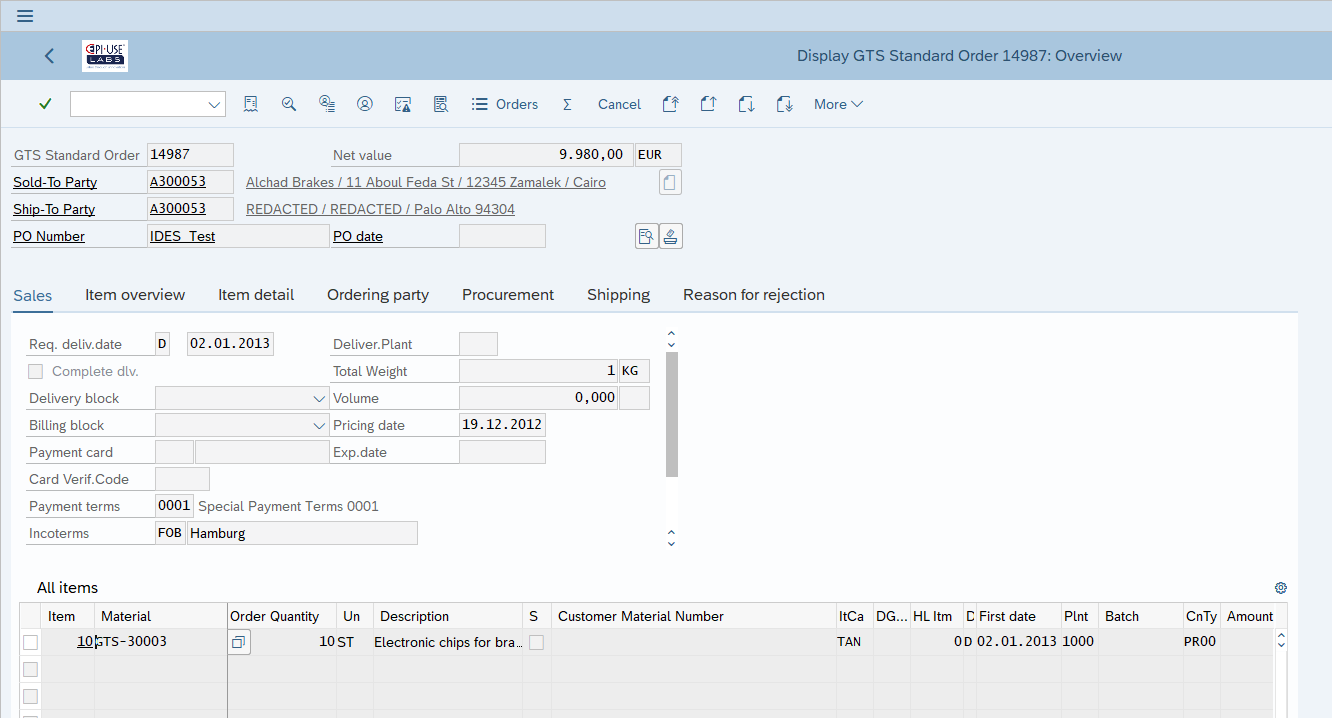
Esempio pratico n. 3: Indirizzi personalizzati negli ordini
Nel blog precedente, mi sono soffermato sul topic degli indirizzi personalizzati o adattati nel quadro del processo di acquisto come “guest” o nel caso in cui l’indirizzo ereditato dal record anagrafico sia stato adattato per questo particolare ordine. Ora qui vediamo un record di indirizzo diverso collegato all’ordine in VPBA in cui, invece, abbiamo offuscato in modo programmatico quei dati in ADCR.
Tutto molto semplice, alla prima impressione, ma... dove sta la trappola?
La sfida quando si decide di concepire da soli un programma di offuscamento personalizzato risiede nella quantità di luoghi in cui i dati possono essere presenti contemporaneamente. Non è impossibile scovarli tutti, ma in questo caso l’intera operazione dovrà essere ripetuta quando il processo cambia o ad ogni futuro upgrade di SAP. Alcuni esempi sono:- documentazione delle modifiche nella tabella CDHR e nel cluster CDPOS
Benché nel nostro processo di mascheramento non vengano generati documenti di modifica, potrebbero essercene alcuni da qualche parte, e questi potrebbero includere modifiche reali, ad esempio un cambio di indirizzo di un cliente. Sia i dati vecchi che quelli nuovi sono informazioni personali per il cliente. - ADRC, ADR2, ADCP, ADRP, ecc.
A seconda della personalizzazione del sistema e del tipo di dati di indirizzo, questi dati personali possono essere conservati in vari campi di diverse tabelle. È fondamentale tracciarli tutti, intervenendo però solo su indirizzi mirati, e non selezionare accidentalmente un indirizzo di personalizzazione, ad esempio. - Cluster di dati
Le tabelle lineari sono in genere più semplici da gestire come lo sono anche i cluster come i CDPOS in cui l’elemento chiave è esterno ai dati di cluster grezzi. Ma in alcuni casi (ad esempio di dati HCM di cui ci occuperemo nel prossimo blog) l’effettivo identificativo è più difficile da individuare, ad esempio il numero del dipendente nel cluster PCL2. Anche la posizione in cui si trovano i dati personali all’interno del cluster può variare da sistema a sistema, in base al paese del dipendente, ad esempio, o ad altre proprietà del record di dati in questione.
Tecnologia di mascheramento di EPI-USE Labs
Abbiamo sviluppato un software che le organizzazioni possono sfruttare per eseguire internamente le operazioni di offuscamento, sia in risposta a specifiche richieste che nel quadro dell’applicazione automatica e periodica di un periodo di ritenzione. Offriamo inoltre servizi e indicazioni per assistervi nelle prime e più significative operazioni di “ripulitura” del debito di privacy che riguarda i vostri dati accumulati. Contattateci se desiderate ottenere l’assistenza dei nostri esperti.
Intervento minimo per soddisfare i requisiti di riduzione dei dati storici per finalità di compliance.

Lascia un commento: