

Pour beaucoup d’organisations, les « meilleures pratiques » des données de test se résument à la conformité. Cela reflète une tendance à se focaliser uniquement sur le problème immédiat. « L’activité » ou la législation ont appelé à la suppression des données sensibles des environnements non-productifs ; c’est donc cet incendie que les organisations tentent de maîtriser en premier.
Même si elle est nécessaire, la suppression des données sensibles des environnements non-productifs occulte deux des principaux défis liés aux données de test d’aujourd’hui. Tout d’abord, cela ne règle pas le problème du temps passé par les testeurs et les développeurs à attendre, trouver et générer des données de test. Ensuite, cela ne prend pas en compte l’impact de données de production peu variées sur la couverture globale du test. Pour répondre aux trois défis posés par les données de test, à savoir, la rapidité, la qualité et la conformité, il est nécessaire d’adopter une nouvelle stratégie.
Le 19 octobre, je rejoindrais Paul Hammersley d’EPI-USE Labs afin d’échanger sur la façon dont les organisations peuvent cibler ces trois défis. Vous pouvez vous inscrire pour nous rejoindre en direct ou sur demande.
Ce blog met en lumière certaines des contraintes liées aux données de test que nous aiderons à résoudre lors du webinaire en ligne, tout en présentant la solution qui y sera abordée.
Données de test : un problème qui ne disparaîtra pas de lui-même
Beaucoup d’organisations actuelles doivent repenser leur stratégie de « gestion » des données de test. S’appuyer sur une équipe centrale pour anonymiser et copier d’importants ensembles de données de production sera toujours un jeu de rattrapage. Pendant ce temps, cela n’améliore pas la qualité des données de test et ne réduit pas le temps passé par les équipes à patauger dans d’immenses ensembles de données ou à repérer manuellement les combinaisons manquantes.
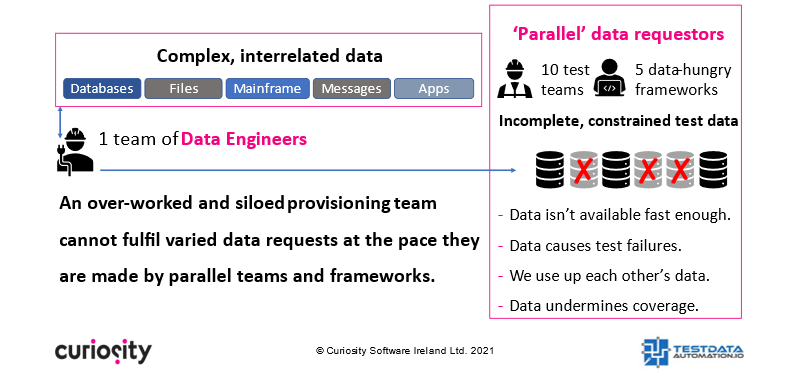
Un certain nombre de facteurs ont augmenté la demande de données de test, ajoutant à l’urgence d’un changement de stratégie. Ces tendances associées ont rendu plus difficile que jamais le provisionnement manuel des données pour fournir des données suffisamment variées, à la vitesse demandée par les équipes et les cadres parallèles. Elles comprennent les éléments suivants :
-
Livraison « agile », DevOps et itérative : grâce à un développement rapide et itératif, les changements et les nouvelles versions candidates n’ont jamais été aussi rapides. Cela requiert un accès continu aux ensembles de données en constante évolution.
-
Tests automatisés et CI/CD : l’exécution de tests automatisés a augmenté le volume et la variété des tests, qui demandent des données à jour. Les tests automatisés sont aussi moins indulgents que les testeurs manuels. Si des données inexactes ou incohérentes sont provisionnées, les tests échouent, ce qui entraîne des pertes de temps car les défaillances doivent faire l’objet d’une enquête.
-
Parallélisation des équipes et des cadres : aujourd’hui, le nombre d’équipes et de cadres essayant de travailler en parallèle n’a jamais été aussi élevé. Ces testeurs parallèles ne peuvent pas s’appuyer sur un nombre limité de copies de données de production. Ils ont besoin de données parallèles, car sinon ils utilisent ou modifient leurs données mutuelles.
-
Parallélisation des tests : les tests automatisés sont plus rapides que les tests manuels et peuvent également être exécutés en parallèle. Il arrive souvent que deux ou plusieurs tests d’une suite de tests nécessitent des combinaisons de données similaires. Cela accroit la demande en matière de données, car les défaillances de test chronophages augmenteront si un test consomme les données d’un autre test.
-
Complexité du système et nouvelles technologies : à mesure que les développeurs adoptent de nouvelles technologies et que les systèmes se complexifient, il devient de plus en plus difficile de répondre à toutes les exigences de dépendance dans les environnements de test. Le masquage et la génération de données, par exemple, doivent anonymiser les données de manière cohérente sur une plage de bases de données et de fichiers. Sinon les tests intégrés et de bout en bout échoueront.
Modernisation des données de test
Les pratiques actuelles des données de test doivent être en accord avec les « meilleures pratiques » disponibles dans les pipelines DevOps et CI/CD. Le « provisionnement » de données doit être automatisé et exécuté en parallèle, tout en étant capable de répondre aux changements « à la demande ». Les demandeurs de données automatisées et manuelles doivent en outre être capables de déclencher les processus réutilisables sur demande, afin de réduire la pression sur les équipes de provisionnement de données surchargées.
Aujourd’hui, il existe de nombreux outils et techniques efficaces pour gérer les différents problèmes liés aux données de test. Ils incluent l’anonymisation des données pour soutenir la conformité, la génération de données pour stimuler la variété et le clonage pour mettre les données à disposition des tests, testeurs et environnements parallèles. La virtualisation de base de données a permis de réduire le temps et les coûts associés à la copie de données, alors que les moteurs de comparaison et d’analyse des données aident les testeurs et les développeurs à comprendre les données.
Vous avez probablement déjà certaines de ces solutions dans votre organisation, soit intégrées en interne soit dans des outils commerciaux. La pièce manquante de nombreuses stratégies de données de test est le processus permettant de combiner, réutiliser et mettre à disposition différents outils sur demande pour les demandeurs de données manuelles et automatisées. Au lieu de cela, la responsabilité est reportée sur une équipe de provisionnement surchargée, qui ajuste et exécute lentement un ensemble de processus linéaires pour chaque demande de données.
Voici à quoi ressemble une stratégie de modernisation en deux étapes pour les données de test :

En d’autres termes, une stratégie complète de données de test doit inclure toutes les technologies nécessaires pour créer des données complètes et conformes en parallèle et sur demande. Ces techniques doivent par ailleurs être standardisées et automatisées, mais aussi exposées aux équipes parallèles, aux cadres d’automatisation et aux pipelines CI/CD. Les demandeurs de données manuelles et automatisées doivent être capables de paramétrer et déclencher les processus de données de test réutilisables sur demande, et recevoir les données dont ils ont besoin à la volée.
Voulez-vous voir cette stratégie en action ?
Mardi 19 octobre, je rejoindrais Paul Hammersley d’EPI-USE Labs pour explorer la façon dont les organisation peuvent passer d’un support de la conformité des données de test à l’implémentation d’une stratégie de données de test moderne. Pour voir comment mettre à disposition des données complètes et conformes à la volée, inscrivez-vous à notre webinaire « Testing across SAP and non-SAP systems: From test data compliance to continuous innovation. »
Leave a Comment: