

Dans le blog précédent de cette série, j’ai abordé le sujet des clients qui attendent d’une société qu’elle gère leurs données, en particulier dans un contexte d’accès « Invité ». Quand ces données seront-elles supprimées définitivement ?
Qui y aura accès avant leur suppression ? Quel est le niveau de sécurité des données stockées ?
Dette envers la protection de la vie privée
Les données de commande « Invité » sont un exemple de la « dette de confidentialité » qui réside dans la plupart des systèmes ERP. Il s’agit de données dont la persistance ne repose clairement sur aucun fondement juridique et qui n’ont en général pas été supprimées en raison de la complexité du nettoyage du système ERP. Cela pourrait également s’appliquer aux systèmes CRM ; mais dans la plupart des cas, ces systèmes ont été conçus en tenant compte du fait que certaines données seront transitoires et incluent des mécanismes de suppression des données qui ne sont plus utiles.
Les principes de base des systèmes ERP, et certainement de SAP ERP, sont en fait à l’opposé : intégration complète et traçabilité de toutes les données à tout moment. J’ai fait une publication à ce sujet lors de la présentation du RGPD et sur les défis qu’il posait pour le « droit à l’oubli ». Cela signifie que la plupart des sociétés qui exécutent SAP se retrouvent avec des données dont elles ne peuvent justifier la présence dans leurs systèmes.
Il existe bien sûr d’autres exemples de « dette de confidentialité », comme les employés qui ont quitté l’organisation depuis longtemps. Plus la relation avec l’employé est libre, plus la période de conservation des données est courte. Il peut s’agir par exemple de travailleurs saisonniers dans les systèmes de distribution qui reviendraient ou non l’année suivante, ou de contractants employés pour un projet à court terme spécifique.
Les employés/clients/fournisseurs qui font partie d’une entreprise qui a été liquidée depuis longtemps constituent un autre exemple commun pour les industries où les acquisitions et les cessions sont courantes. Ou encore des données présentes dans un système qui a été repris lors d’une acquisition, mais qui n’a jamais fait partie de l’activité achetée. Il y a dix ans, la confidentialité des données n’était pas prise en compte lors des acquisitions. Le transfert des systèmes et des données nécessaires à l’exécution de l’activité était le seul objectif du projet technique et si quelques données supplémentaires étaient incluses, qui s’en souciait ? Aujourd’hui, les projets de fusions et acquisitions doivent prendre la confidentialité des données très au sérieux, comme pour tout autre projet -
« Par défaut et par conception ».
Supprimer les données dans SAP, archiver (SAP ILM) ou rien
La suppression des données des systèmes ERP et en particulier de SAP présente deux défis majeurs :
- La traçabilité des modifications dans le système
Si les utilisateurs fonctionnels modifient les données via les transactions standard, le système enregistre les modifications et par conséquent les anciennes données aussi, par exemple, les documents de modification fournisseur/client/partenaire :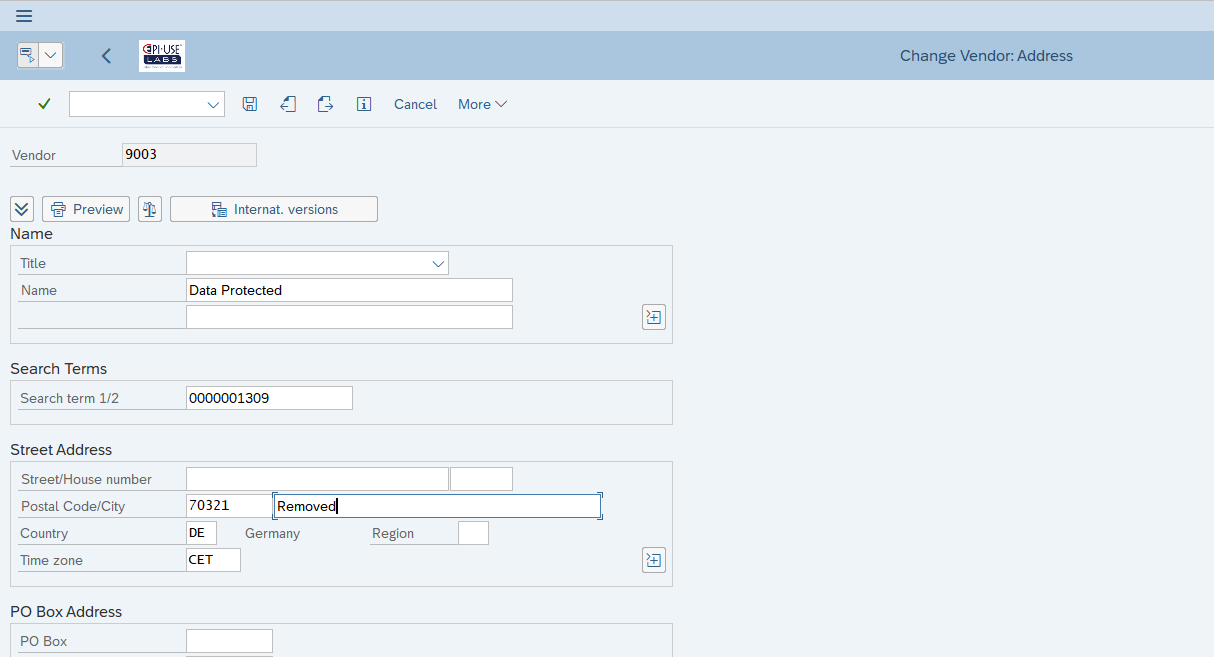
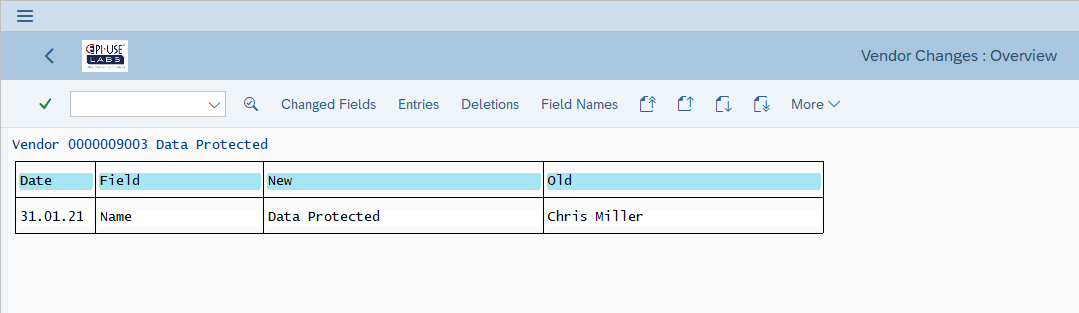
- L’interconnectivité des systèmes ERP
Si à la place nous allons directement au niveau de la table pour supprimer les enregistrements contenant ces données personnelles, des incohérences apparaitraient dans le système. Par exemple, les commandes clients faisant référence à une clé principale client qui n’existe plus.
Le seul moyen standard de supprimer des données pour qu’aucun de ces défis ne soit un problème est de marquer les données pour suppression et de les archiver. Cela déplace les données dans un fichier distinct sur le système d’exploitation, en général dans un emplacement où les données peuvent toujours être lues par le système SAP, mais pas modifiées. L’objectif de l’archivage n’a jamais été de supprimer les données personnelles historiques du système, mais en supprimant les fichiers d’archives, on peut arriver à ce résultat. En revanche, le gros problème est que le processus d’archivage requiert d’archiver d’abord les transactions qui référencent les données de base. Et pour archiver chaque transaction, vous devez d’abord archiver toutes les transactions suivantes. Donc, par exemple, pour archiver les données de base client, nous devons d’abord archiver les commandes clients mais pour archiver les commandes clients, la livraison doit d’abord être archivée... jusqu’aux documents comptables. Ce processus n’a pas été conçu pour simplement supprimer les données personnelles ou sensibles et cela se voit lorsqu’on l’applique à ce défi.
S/4HANA dans le mix
Que serait un blog SAP sans la mention de S/4HANA ? Eh bien, lors de la réflexion ou de la préparation d’une migration S/4HANA, le nettoyage et l’archivage des données sont en général discutés. À ne pas confondre avec la gestion de la dette de confidentialité. Le nettoyage des données concerne rarement celle des données non requises, à moins qu’il s’agisse d’un projet de construction dans lequel cette dette en attente peut simplement être laissée de côté. Typiquement, il s’agit du processus ICF (Intégration client/fournisseur) et la déduplication des fiches utilisateur ou la correction des erreurs de formatage. L’archivage est pris en compte dans les projets Brownfield pour réduire la taille potentielle de la future base de données du système, la majorité des gains d’espace étant archivée en retirant d’importants volumes de données de transaction plutôt que de données de base historiques.
L’alternative : « Rédacter »
Si le nettoyage complet de la dette de confidentialité ne génère pas de gain d’espace majeur, et que le processus créé davantage de difficultés en supprimant potentiellement des données non sensibles de valeur comme la couverture géographique des clients, la fonction de reporting de genres sur les employés historiques, il existe surement un meilleur moyen ? Le problème avec le fait de laisser l’entreprise simplement modifier les données pour supprimer les valeurs identifiables est que la modification en elle-même fait l’objet d’un suivi. Si nous préférons aller directement au niveau de la table pour remplacer des données sensibles ou d’identification, nous pouvons le faire dès le début de l’existence des données et non en tant que modification, comme c’est le cas actuellement.
Mais toutes les informations connexes qui peuvent toujours être utiles pour le reporting peuvent être conservées. Et toute dépendance de relations de clé étrangère dans les données transaction, ou même les références de données de base liées (par exemple, adresses, données d’OTP, contacts) seront toujours intactes.
Exemple pratique 1 : fiche fournisseur
Ici, vous voyez le même fournisseur que tout à l’heure, mais maintenant, nous avons rédacté les données sensibles dans LFA1, LFB1, ADRC au niveau du programme.
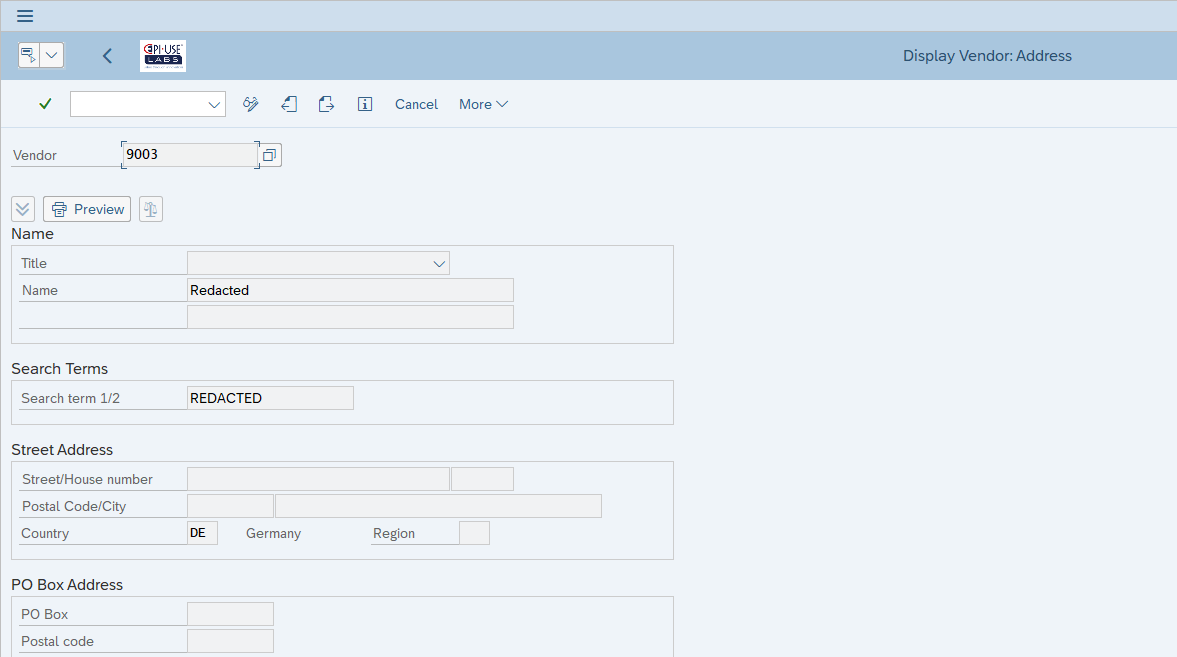

Avec tous les documents de modification supprimés (puisque les valeurs d’origine peuvent s’y trouver).
Exemple pratique 2 : fiche client dans les commandes
Dans cet exemple, les données de base de KNA1, ADRC, etc. qui sont gérées via XD02 sont visibles dans la transaction Commandes clients (VA03) en raison du lien dans la table VPBA. Nous n’avons pas besoin d’apporter de modifications à la commande dans cet exemple. Toutes les données personnelles sont retirées. Donc les modifications, similaires à ce que nous avons fait dans le premier exemple pour le fournisseur, et maintenant dans la fiche client, garantissent aussi que les commandes pour ce client ne présentent plus de données personnelles.
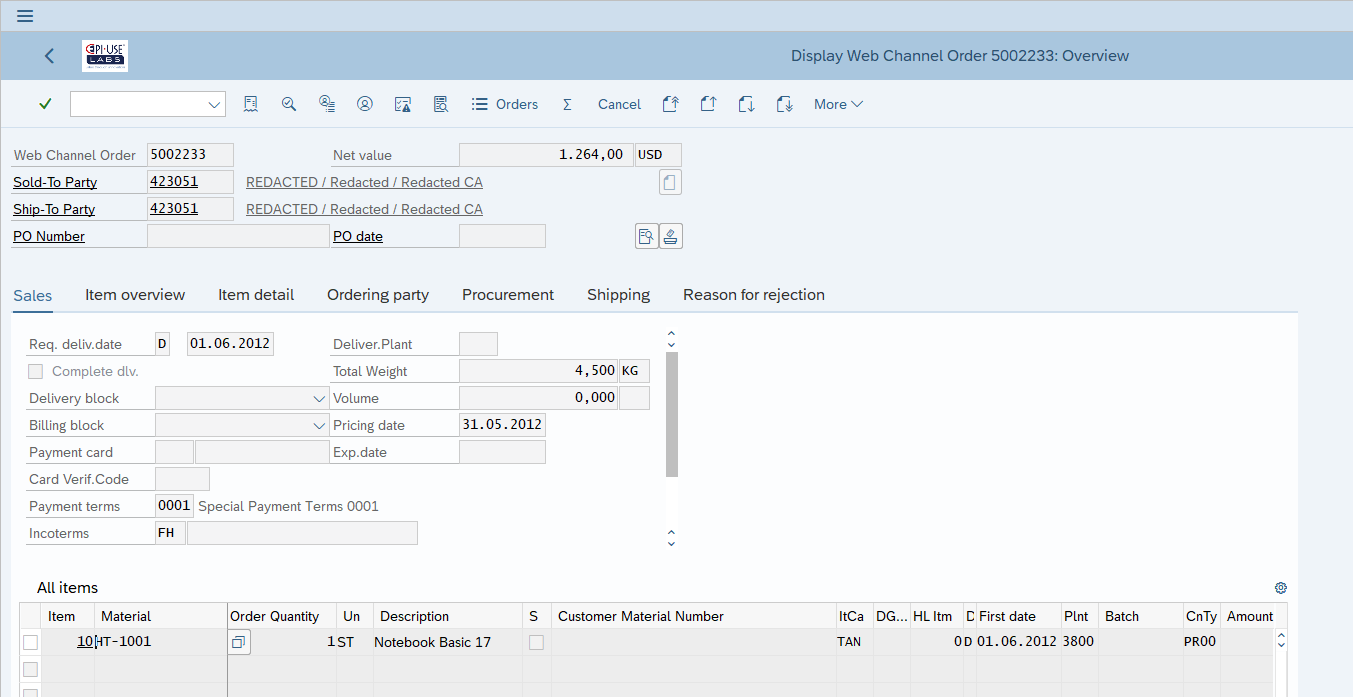
Exemple pratique 3 : adresses sur mesure dans les commandes
Dans le blog précédent, je m’étais concentré sur le sujet des adresses personnalisées ou sur mesure, comme faisant partie d’un processus d’achat « Invité » ou dans lequel l’adresse héritée de l’enregistrement de données de base a été adaptée pour cette commande particulière. Maintenant, nous voyons un enregistrement d’adresse différent lié à la commande dans VPBA et avons à la place effacé les données dans ADRC au niveau du programme.
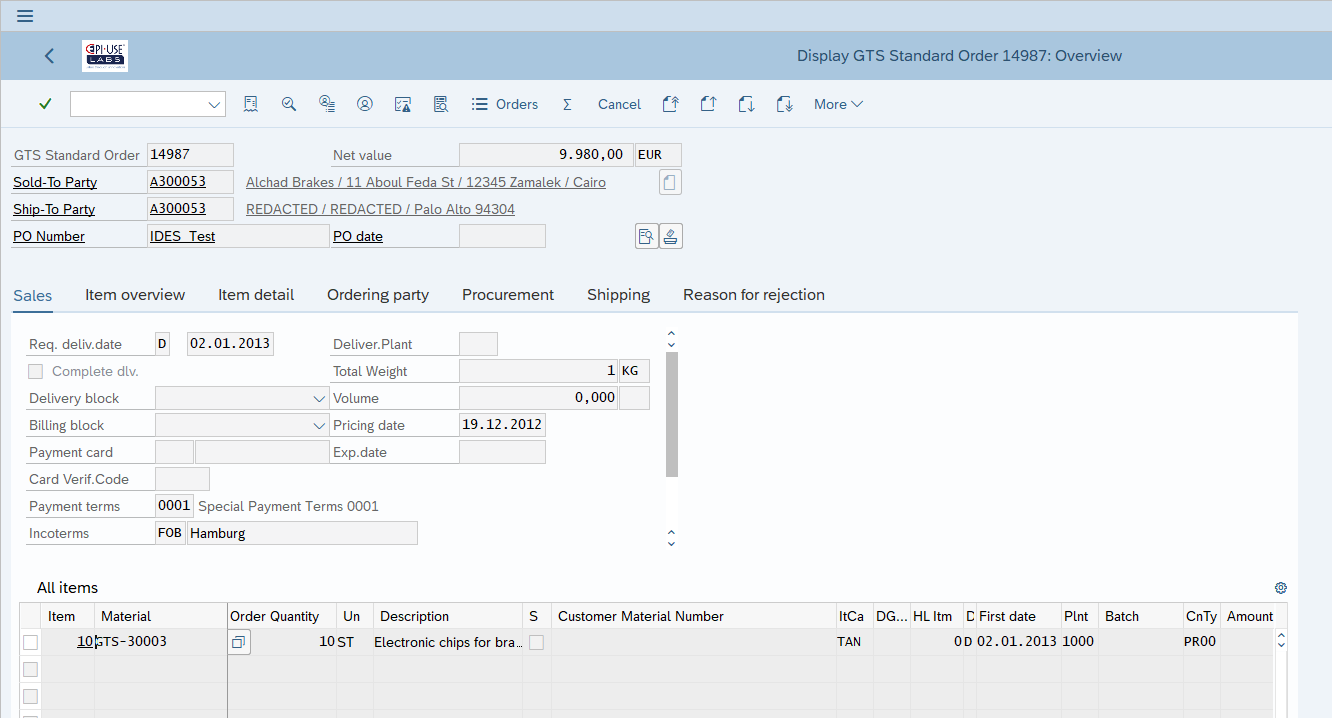
Tout cela semble assez simple - alors où est le piège ?
Le défi avec la configuration de vos propres programmes de «rédaction» est le nombre d’emplacements dans lesquels les données peuvent aussi résider. Il n’est pas impossible de tous les trouver, mais c’est quelque chose qui doit aussi être vérifié si les processus de gestion changent et lors d’une future mise à niveau de SAP. Voici quelques exemples :
- Documents de modification dans la table CDHR et le cluster CDPOS
Même si nous ne générons pas de documents de modification dans notre processus de «rédaction», il peut en exister et ceux-ci peuvent inclure de réelles modifications - par exemple le changement d’adresse d’un client. Les anciennes et nouvelles valeurs sont des données personnelles de ce consommateur. - ADRC, ADR2, ADCP, ADRP, etc.
En fonction de la personnalisation du système et du type de données d’adresse, les différents champs des différentes tables peuvent stocker ces valeurs de données personnelles. Il est essentiel de tous les suivre mais de n’affecter que les adresses visées et de ne pas prélever accidentellement une adresse de personnalisation par exemple. - Données de cluster
En général, les tables transparentes sont faciles à gérer, de même que les clusters comme CDPOS dans lesquels la clé est en dehors des données de cluster brutes. Mais dans certains cas (comme les données HCM que j’aborderai dans le prochain blog), l’identificateur réel est plus difficile à repérer - par exemple, le numéro d’employé dans le cluster PCL2. L’emplacement des données personnelles dans le cluster peut aussi varier d’un système à l’autre, voire d’un enregistrement à l’autre, en fonction du pays de l’employé par exemple, ou d’autres propriétés de l’enregistrement de données particulier dans le périmètre.
Technologie de «rédaction» d’EPI-USE Labs
Nous avons développé un logiciel qui peut être exploité directement par les organisations pour réaliser leur propre «rédaction», soit en réaction aux demandes individuelles, soit dans le cadre de l’application périodique automatique d’une période de conservation. Nous proposons également des services et des conseils pour aider à gérer le nettoyage initial majeur de la dette de confidentialité.
Contactez-nous pour obtenir l’aide de nos experts.
Activité minimale pour satisfaire les exigences de minimisation des données historiques pour la conformité.
Leave a Comment: