Make it easy to keep your multiple instances and employee data synced and secure, in your SuccessFactors and ABAP landscapes
SAP SuccessFactors introduced tools very early on to assist with privacy legislation compliance for your Production instances. You can read more about this in Raghavendra Kumar’s excellent blog including support for Data Subject Access Requests, purging of historical data, blocking data from some users and Read Access logging.
But beyond the Production SuccessFactors instance, the same data is often residing elsewhere. In this short blog, I’ll talk about where that is, and what you can do about it:
- Testing is only as good as the data and customising
- Managing sensitive data after an Instance Refresh
- Complications for hybrid environments
Testing is only as good as the data and customising
All customers require secure access to their critical HCM and Payroll Production data in non-production systems for testing, training and support. Customers in SAP SuccessFactors hybrid scenarios or with SAP SuccessFactors Employee Central Payroll currently have limited options for how to accomplish this.
Without aligned configuration and data, the testing is, at best, compromised. The quality of the test data also has a big part to play. Just like in the on-premise SAP systems, there is no easy way to generate synthetic realistic test data, and so real Production data is generally favoured. At a high level, SuccessFactors customers have limited options for moving and masking data between their environments:
-
Instance Refresh – A customer can request that they get a copy of the entire instance (test becomes a copy of Production for example), or
-
Instance Sync – They have limited abilities to move entities and their properties from one environment to another. Typically, this would be used for a specific set of Foundation objects, but it is not always successful because of config. differences.
In respect of the Instance Refresh, SAP is now introducing a self-service option to request an ‘automated’ instance refresh for any instance under 200GB. This will be introduced with the 2H-2020 release.
In terms of the Instance Sync, this will eventually be replaced by the Configuration Center which is soon to be opened up to early adopters for beta testing (watch this blog thread for more information on this). The Configuration Center, though, is going to be focused on the settings that determine how the system behaves, and some foundation objects. The actual employee data is not in scope for this (as the name would suggest). So for the foreseeable future, the standard options are only leading to an Instance Refresh if you want to test with accurate data.
There are some third-party tools which can assist with copying individual employee data down to test instances, including EPI-USE Labs’ Data Sync Manager™ (DSM) Object Sync for SuccessFactors Hybrid, which also includes masking of data consistently with any backend ABAP stack, or ECP system. This solution is SAP certified. Also good to note is that this product is whitelisted to run on SuccessFactors Employee Central Payroll as per SAP Note 2167337, and does not require a license for SCP.
Managing sensitive data after an Instance Refresh
Let's focus now on how to handle sensitive data in an instance which has been refreshed. Immediately, the employee names, addresses, emergency contacts etc. are available in a system which may not have Role Based Permissions which are as tightly controlled. And sometimes these non-production instances are made available to external contractors, or partner organisations, sometimes in remote geographies (creating issues around data transfers). If the data is for a European citizen, can we build legal grounds for using their data for testing purposes? SAP’s own data processing agreement directly states that real data should not be in test environments (read more in our blog). Fortunately, all the standard portlets storing sensitive information are linked to an OData entity which can be leveraged to update the system via an API call.
This is how our DSM engines can copy and mask test data. Here are some of the critical entities and the data they typically store. Please keep in mind that via MDF, organisations can adapt these definitions, and it's quite common to see duplication of sensitive values like ‘name’ in a custom property. In some cases, the standard property may exist but isn’t populated.
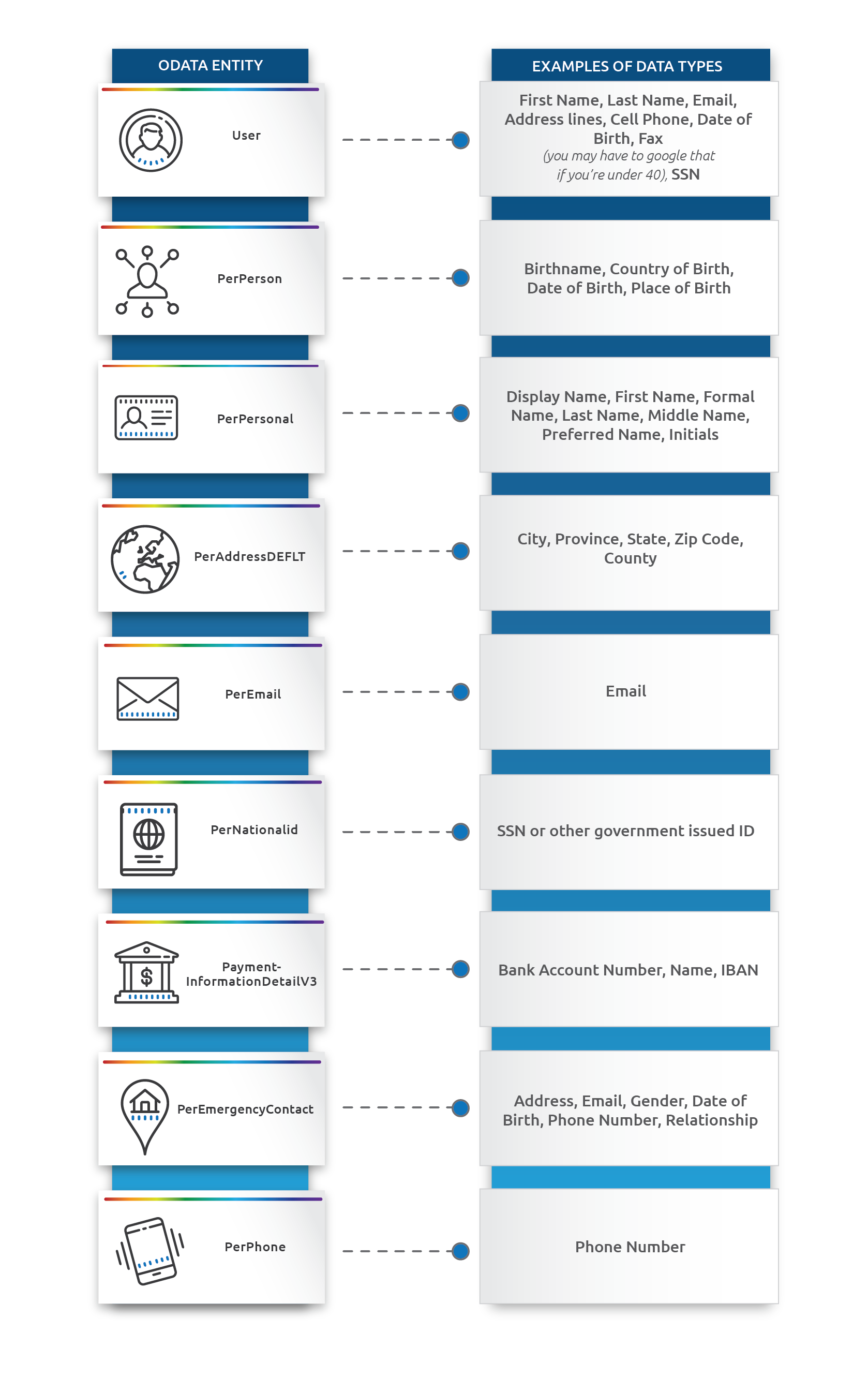
(Click image to enlarge)
Just like in the traditional SAP ABAP systems, customers often underestimate the level of effort for creating code or scripts to update these types of fields.
Either the main system itself, or systems which interface from it, may have validations on formats particularly when it comes to fields like postal codes, bank account numbers or government IDs. In some cases, these validations can change. For example, we’ve recently seen a dummy phone number in PerPhone which had a ‘-’ in the third character position, which is suddenly not accepted by the OData API because of the format.
Sometimes, just the interdependence of the data records being changed can make it harder to provide realistic-looking test data. For example, maintaining the same surname between the employee themselves and their emergency contacts. In how this is achieved, it's also important not to cleanse the data. Take the example of the User-email and PerEmail-emailAddress; it might be assumed that these will be the same for an employee, and the masking routine may be hard coded to apply the same value to both. But what if that was a data inconsistency in the real data in Production? That could be the very cause of the Production support issue which is resulting in someone using the scrambled record in the test system, and hence the same issue may not occur in the test instance.
It’s also important to consider that some users of the scrambled instance may have access to additional outside data that could be used in conjunction with the scrambled data, and might allow them to try to reverse engineer the scrambling. It's important that the routines applied do not leverage a simple seed table or mapping table where someone can start to unpick the mappings. Instead, pattern breaking should be used to make sure that not every John becomes a Tom.
Complications for hybrid environments
If a SuccessFactors instance is replicating data to either an ECP or on-premise SAP HR/Payroll system, there are two additional considerations:
1) Not all ECP/on-premise personal data can be updated by replication
The replication affects the main infotype tables, but significant amounts of personal data are duplicated from those tables into other infotypes, country-specific payroll tables, cluster tables and in some cases even the temse database. For example, the name, address and government ID typically stored in the RT payroll cluster is recorded from the infotype data when payroll was run. So changing those values via replication, even if the start date of the replicated record is the earliest one, will not change what’s already been written to the cluster. To effectively protect identities or values which are sensitive, there will need to be some update occurring directly on the ABAP side. Ideally, the values used should match the values for the same employee in SuccessFactors.
2) Privacy-related activities not supported by delivered functionality in the ECP/on-premise system
Some of the SuccessFactors functionalities we mentioned at the start of the blog, as discussed by Raghavendra for data privacy in the Production instance, do not have an equivalent set of capabilities in the ECP/on-premise system. Managing Subject Access Requests, removal of data as it passes the retention period, etc., are things organisations must work out for themselves, or leverage a third-party solution for. Any processes or technologies leveraged will need to consider just how much overlap there is between SuccessFactors and the backend ABAP system, and manage both together effectively.
Insights from SAP experts and industry leaders
Subscribe todayHCM productivity suite with you every step of the way in your HCM journey